2024-05-24-금 수정
드디어 한자 공부를 포기하고 Excel로 간단한 한자 번역기를 만들었다. 한자 번역기는 그냥 한자 찾아서 훈독을 한자 밑에 나열하는 것이다. 이것들을 만들면서 알게 된 내용이다.
1. 완성형 한자 번역기 (KSC5601, CP949, EUC-KR)
위와 같이 입력하면 아래와 같이 나온다는 것
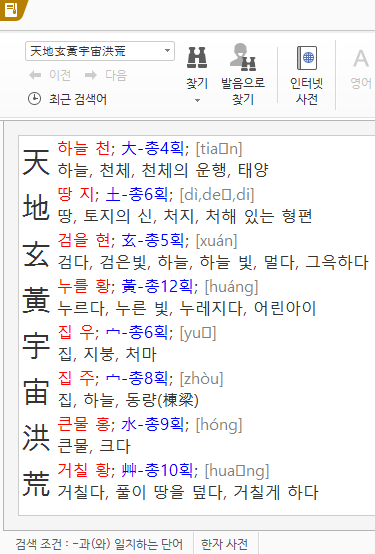
천자문을 번역해 보았다. 어라? 완성형 한자에 없는 글자도 있네? 완성형 한자는 도대체 정체가 뭐냐? 참고로 천자문 외우는 순서는 4음절씩 끊어서, 16자를 한 문장으로 노래처럼 독음부터 먼저 익힌다. 그 다음에 의미를 외우고 한자의 형태는 나중에 외운다. 왜? 노래는 잘 외워지기 때문이다. 먼저 노래로 틀을 잡고 골치 아픈 한자의 모양은 나중에 외우는 것이다.
위키백과천자문링크
번역기를 만들려고 한자를 빨기 찾기 위해서 한글 완성형 문자표를 찾아보니 규칙이 있더라. 4888자가 94개씩 끊어서 배치되어 있다. 고로 한자의 코드(정수)만 알면 간단하게 한자 위치를 계산해서 한자의 훈독을 검색할 수 있다.
위의 표는 16비트 문자를 해독하는 표이다. 바이트의 첫 비트가 0이면 7비트 아스키 코드로 해석하고, 첫 바이트의 첫 비트가 1이고 그 다음 바이트의 첫 비트도 1이면 한글 완성형 문자로 해석하는 것이다. 그런데 소심하게도 제어 문자를 피하기 위해서 노란 영역만 사용한 것이다. 어떤 기계는 첫 비트가 1임에도 ASCII 코드로 해석할 수도 있으니까. 표준 만드는 놈들 도대체 뭐 하는 거야?
주황색은 뭐냐? 한글 처리가 불편해서 모든 한글을 MS사에서 추가 배치해 준 영역이다. 왜 저 영역에 배치했는지는 비전문가라 잘 모르겠다. 우리 너무 불쌍하지? 한글 넣으면 한자 못 넣고, 한자 넣으면 한글 못 넣는 거지. 한국에서만 사용할 각오 하고 과감하게 정했다면 모든 한글과 한자를 넣을 수 있었는데 말이지. 너무 소심해. ㅋㅋㅋㅋ
위는 검색 표이고 아래는 검색하는 VB Macro 코드이다
a = Mid(buffer, i, 1) '문장에서 한자 하나 가져 오기
b = Asc(a) '한자의 문자 코드 얻기
If b >= -13663 And b <= -514 Then '한자라면
c = Int((b + 13663) / 256) * 94 + (b + 13663) Mod 256 + 2 '위치 계산
d = Worksheets("사전").Cells(c, 5).Value '독음
e = Worksheets("사전").Cells(c, 6).Value '의미
Else '한자가 아니면
End If
Excel VB Macro에서 한자를 문자 코드로 바꾼 후에 한글, 영문, 그림 문자가 아닌 한자 영역에 속하면 한자의 위치를 계산해 주는 코드이다. Asc(문자) 함수는 문자의 완성형 코드 값을 준다. Int((b + 13663) / 256) * 94는 코드표에서 행의 시작 위치이고 (b + 13663) Mod 256는 코드표에서 열의 위치이다. 마지막 2는 Excel Sheet에서 첫 행은 제목으로 쓰고 이 행 번호가 1이라서 2행부터 한자 사전이 시작하도록 했기 때문이다. 한자 사전은 Naver나 Daum에서 홀라당 베끼면 된다.
2. 유니코드 한자 번역기
유니코드 한자도 번역을 해 보자. 유니코드가 되면 중국어, 일본어 한자도 번역을 할 수 있다. 윈도우즈나 Excel에서도 유니코드를 사용할 수는 있다. VB Excel Macro에서는 유니코드를 사용할 수 없다. 코드 작성 화면에 표시하거나 파일로 저장할 수 없을 뿐이고 내부적 변수 저장과 계산 처리는 모두 유니코드로 할 수 있다. 고로 다음과 같은 Excel 함수를 이용하면 VB Code에서 직접 유니코드를 얻어 빠른 검색이 가능하다.
유니코드 표를 보면 모든 영역(65536개)을 다 사용하기 때문에 한자 & 한글 처리가 편하다. 완성형처럼 띄엄띄엄 배치 되지 않고 연속적으로 배치 되어 있어 위치 계산이 쉽다. 그런데 이상하게 한자들이 흩어져 배치 되어 있다. 유니코드 V1.0 한자 20902개는 주황색이다. 그런데 초록색으로 표시 된 한자 영역이 또 있다. 한글 워드에서 확인해 보면 훈독도 표시 되지 않는 한자들이다. 왜 이런 바보짓을 하는 것인지 모르겠다. 표의 바닥 쪽에 배치된 것은 정말 거의 쓸 일 없는 것들인데 어떤 바보들(한국/일본인?)이 만든 코드들과 호환성을 위해 할당한 것으로 보인다.
Public Function vb_unicode(a)
'문자를 유니코드 값으로 변경
vb_unicode = Application.WorksheetFunction.Hex2Dec(Hex(AscW(a)))
End Function
a = Mid(buffer, i, 1) '문장에서 한자 하나 가져 오기
b = vb_unicode(a) '유니코드로 바꾸기
If b >= 19968 And b <= 40869 Then '유니코드 한자라면
r = b - 19968 + 2 '위치 계산
d = Worksheets("사전").Cells(r, 3).Value '독음
e = Worksheets("사전").Cells(r, 4).Value '의미
Else '유니코드 한자가 아니라면
End If
VB 함수 중에 AscW()는 유니코드를 준다. 그런데 16비트 정수로 표현하다 보니 양수와 음수로 영역이 나뉜다. (왜 이런 바보 같은 짓을 할까? 그냥 양수로 주지 귀찮게 하네!) Excel 함수를 이용해서 Hex(16진수) 표현으로 바꾸고 다시 Dec(10진수)로 바꾸면 모두 양의 정수로 표현이 된다. 한자 시작 유니코드 값을 빼고 2를 더하면 한자 사전에서 행번호가 나온다. 첫 행이 1이고 제목 행이기 때문에 실제 데이터는 2행부터 시작이다. 이렇게 직접 행 번호로 검색하면 아주 빠른 번역이 가능하다.
천자문을 다시 번역해 보니 유니코드 한자도 번역이 되었다. 인터넷에서 중국어와 일본어를찾아 검색하여 넣어 보니 신기하게 된다. 하하하하 매우 통쾌하다. (허나 초록색 영역의 이상한 한자들은 번역이 안 되는데...) 이건 모든 나라의 문자가 일단 O/S나 Excel 내부적으로 유니코드로 바뀌어 처리 되기 때문에 가능한 일이다. 이 방법으로 어떤 나라의 언어도 번역할 수 있다. 자 그럼 본격적으로 외국어 번역기도 만들어 볼까? 물론 단어 번역기 수준이겠지만 그래도 외국어 공부하는 것보다는 시간 절약 될 것 같다.

여러 훈독을 보기 불편해서 한컴 사전처럼 세로로 한자를 나열해서 훈독을 옆에 표시하는 기능을 추가 하자. 옛날 한컴 사전은 한자 2~3개만 번역을 해 주었다. 그래서 불편해서 모든 한자를 번역하는 기능을 만들었는데 요즘 한컴 사전에서도 해 주고 있다. 좀 빨리 해 줬으면 내가 삽질 할 이유가 없었는데 소프트웨어 만드는 사람들도 참 답답하다. 역시 뭐든 사용자가 만들어야 제대로 만든다.
선동 언론을 너무 믿지 말자.
달 착륙 쇼 : 케네디 시절에 “그래 씨발 우리 달에 갔다”라고 정리한 사건?
911 테러 자작극 : 부시 시절에 전쟁 여론을 만들기 위해 언론인이 참여한 자작극?
천안함 폭침 선동 : 이명박 시절에 천안함 폭침으로 몰고 가서 북한 엿 먹인 사건?
세월호 자침 음모 : 박근혜 시절에 국정원 소속 세월호가 이상한 회전으로 넘어진 사건?
왜 이상한가?
달에 인간을 보내는 것은 매우 위험한 짓이다. 우주 방사선, 기계 고장 등으로 죽는다.
그러나 달에 간 증거 또한 무수히 많다고 하니 우리가 직접 가 보지 않은 이상 판단 보류.
요즘은 화성에 갈 준비 한다더라. 우주 방사선을 흡수할 대형 물통을 가져가야 한단다.
물통 안에 들어가 있어야 방사선을 막을 수 있다나? ㅋㅋㅋ
확실히 빌딩 폭발은 폭파 공법으로 무너졌다. 비행기가 이상하다. 진짜 비행기였나?
그러나 빌딩이 무너졌고 죽은 자들의 무덤도 있기 때문에 진실에 대한 판단은 보류하자.
이 사건 핑계로 탈레반 잡고 이라크 털어 먹었다. 미국이 깡패라는 걸 그대로 보여준 것.
폭파 공법으로 무너지는 빌딩은 위부터 아래로 차례차례 무너진다. ㅋㅋㅋ
천안함 폭침 증거는 발견되지 않았는데 좌초, 충돌 증거는 있다. 뭔가 숨기는 정부.
훈련 중에 급부상하는 잠수함과 충돌로 의심이 되는데 거의 99% 신뢰도.
한국 쪽팔리게 하는 사건들을 너무 많이 저질러서 이건 거의 믿어도 된다.
북한 해군이 세계 최강인가 한국 해군의 실수인가. 난 후자를 믿을 거야.
신상철 검색해 볼 것.
세월호는 국정원 소속, 이상한 급회전, 해경의 구조 방해, 정부의 조사/인양 거부.
이것도 미국 잠수함과 충돌이란 주장이 있는데 매우 그럴 듯하다. 99% 신뢰도.
보통의 해상 교통 사고였다면 굳이 원인 조사를 안 하겠다고 버틸 이유가 없다.
엉뚱한 사람만 마녀 사냥 당해 시체가 벌판에 버려진 꼴이 되었다. 누군 또 자살하고.
신상철씨의 분석으론 엔진 하나가 꺼진 상태에서 회전해서 넘어졌다고 한다.
그렇다면 왜 원인 분석을 숨긴 것인가? 7시간 동안 어디서 뭘 했는지 숨기기 위해서?
박정희 시절, 아니 전두환 시절인가?
KAL기 증발 사건을 기억하자.
언론이 그렇다고 하면 믿어야 하나?
뭔 놈의 간첩들이 몇 년 살다 풀려나서 돌아다니지?
여객기까지 폭파시킨 간첩을 왜 사형시키지 않냐?