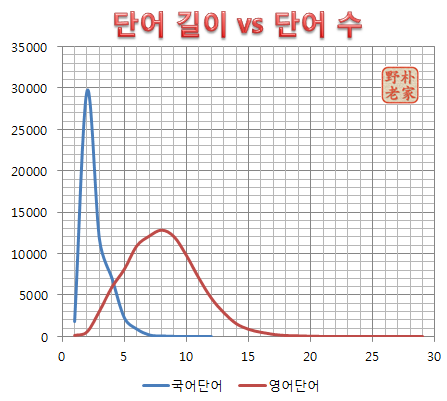
2024-05-24-금 수정
한자는 절대 외우기 쉬운 문자가 아니다. 그러니 조급하게 생각할 필요 없다. 죽기 전까지 시간은 아주 많다. 느긋하게 평생 외우면 설마 못 외우겠는가? 쓸 데는 없으나 치매(癡呆:어리석음) 방지용이라고 생각하고 놀이 삼아 외우자. 한자는 문자가 아니라 기억력 시험, 기억력 과시라고 생각하자.
비슷한 것들은 묶어서 외워야 미세한 차이 구분이 가능하다. 어떤 기준으로 묶을 것이냐? 그건 그때그때 다르다. 독해용으로 모양이 비슷한 것들끼리 묶을 수도 있고, 작문용으로 의미를 기준으로 묶을 수도 있다.
한자엔 비슷한 모양이 많은데 비슷한 모양을 찾아 정리하는 것은 대단히 힘든 중노동이다. (내가 그걸 했다 씨발) 그런데 잘 생각하면 힌트가 있다. 획수가 비슷하거나 독음이 비슷한 경우, 모양도 비슷한 경우가 많다. 단순한 한자의 경우 모양이 비슷하면 부수도 같은 경우가 많다. 즉 부수로 검색하면 비슷한 한자가 모여 있다. 획수, 독음, 부수를 이용해서 정리하면 아주 쉽게 비슷한 한자들을 근처에 배치할 수 있다.
비슷한 것들은 묶어서 외워야 미세한 차이 구분이 가능하다. 어떤 기준으로 묶을 것이냐? 그건 그때그때 다르다. 독해용으로 모양이 비슷한 것들끼리 묶을 수도 있고, 작문용으로 의미를 기준으로 묶을 수도 있다.
한자엔 비슷한 모양이 많은데 비슷한 모양을 찾아 정리하는 것은 대단히 힘든 중노동이다. (내가 그걸 했다 씨발) 그런데 잘 생각하면 힌트가 있다. 획수가 비슷하거나 독음이 비슷한 경우, 모양도 비슷한 경우가 많다. 단순한 한자의 경우 모양이 비슷하면 부수도 같은 경우가 많다. 즉 부수로 검색하면 비슷한 한자가 모여 있다. 획수, 독음, 부수를 이용해서 정리하면 아주 쉽게 비슷한 한자들을 근처에 배치할 수 있다.
1. 부수로 묶기

옥편을 그대로 베껴서 부수 순서 그대로 (같은 부수 안에선 획순으로) 정리하는 방법도 있는데 획수가 비슷하면 모양도 비슷하기 때문에 비슷한 한자를 근처에서 찾을 수도 있겠으나 그런 경우는 매우 드물고, 부수는 의미상 품사 구분 역할을 하기 때문에 의미로 묶는 효과도 있다. 여기서 독음은 거의 한 한자에 하나가 할당 되어 독음으로 묶어도 소용없다.
상용한자, 완성형 4888자에서 삼수변은 가장 많은 한자를 가지고 있다. 물과 관련된 명사, 동사, 형용사, 부사는 모두 모였다. 이 삼수변 우측의 한자는 다른 한자에서도 자주 보는 부품한자들이다. 고로 이 삼수변과 또 다른 세력 큰 부수 몇 개의 한자를 외우면 다른 한자의 독음을 쉽게 유추할 수 있다.
부수 한자 대부분도 역시 중고교 한자이다. 한자 공부할 때마다 봐서 외운다.

2. 의미로 묶기






숫자, 요일(시간), 방향(공간), 색상(시각) 등 의미로 묶을 수 있는 것들이 아주 많다. 특히 형용사의 경우 상대적인 의미가 짝을 이룬 것들이 많다. 어떤 언어에서나 기본인 이런 것들은 중학 수준의 한자이다. 10천간 12지지가 있나 봤더니 역시 중학 수준 한자로 들어가 있다. 동양의 10진법과 12진법을 나타낸다. 한자 요일은 음양오행에서 왔다. (팔괘 이름은 상용한자에 포함되지 않았군. 별로 볼 일이 없으니까.)
이것들은 의미상 함께 묶인 것이다. 이렇게 의미상으로 관련 있는 것을 찾아 묶어 정리하면 작문할 때 편리하다. 예를 들어 사람, 동물(하늘/땅/바다), 식물(나무/풀/꽃/열매), 물질, 건물, 지형 등으로 분류해서 가지고 있으면 작문할 때 도움이 된다. (허나 한자로 작문할 일이 없으니)
대부분의 한자 단어가 2~3 음절로 사용 된다. 한 음절이 한 단어인 경우는 그 수가 많지 않다. 문법 단어이거나 고대부터 자리를 굳힌 단어들이다. 문명 시대에 만들어진 단어들은 대부분 2음절 이상이다. 한자 단어로 묶는 것도 의미 중심으로 묶는 것이다.

네이버, 다음 파자 검색기를 통해서 비슷한 모양을 가진 한자(형성/회의)를 검색할 수 있다. 모양이 비슷해서 헛갈리는 복잡한 한자들은 묶어서 외우면 차이점에 집중해서 구분하기 쉬워진다. 이렇게 하는 것은 한자 판독 능력 향상에 아주, 매우 도움이 된다. 그런데 네이버, 다음 파자 검색기는 완벽하지 않다. 약간 엉터리다. 빠진 한자들이 많다. 100% 믿지 말라.










파자 검색기로 검출되지 않는 단순하면서 매우 비슷한 한자도 많은데 이건 부수+획수로 검색하면 찾기 쉽다. 같은 부수인 경우가 많다. 어떤 것들은 같은 한자를 2개, 3개 반복하는 경우도 있다. 이런 것은 의외로 잘 외워진다. 좌우대칭인 경우도 잘 외워진다. 눈에 띄면 그 때마다 정리해야 한다. 이렇게 정리하는 것은 아주 힘든 중노동이다. 필요한 것들만 이렇게 정리한다. (내가 이걸 정리 했다 씨발)





비슷한 크기로 좌우 결합, 상하 결합한 한자의 경우 어느 것이 부수인지 파악하기 어렵다. 그런 것은 거의 기초 한자다. 이 중에 상하로 결합한 것들, 그 중에 단독으로 거의 사용하지 않고 다른 한자의 부품 한자로 많이 보이는 것이 있다. 고로 세로로 결합한 것들은 모두 기초 한자로 외워두면 좋다. 좌우대칭, 같은 형상 반복, 상하결합 한자는 보면 기초 한자라고 생각하고 모아둔다.
옛날엔 한문을 세로로 적었기 때문에 세로로 결합한 한자가 아마도 헛갈렸던 것 같다. 세로로 결합한 한자는 점차 단독 사용이 줄고 옆에 부수가 추가 된다. 예를 들어 원래 한자도 A라는 뜻인데 좌우에 부수가 추가 되어도 같은 A라는 뜻인 경우가 많다. 가로로 결합한 한자는 그냥 그대로 계속 쓰인 것 같다.
소리로 묶을 경우는 피곤하게 파자 검색기를 사용하지 않고도 쉽게 형성 문자들을 함께 모을 수 있다. 대신 소리를 초성, 중성, 종성으로 나누고 초성과 중성은 다음과 같이 나누고 가나다 순서를 좀 바꿔야 한다.

초성, 중성에서 비슷한 소리가 이어지도록 순서를 정한 후, 소리 사이의 거리와 획수(부수 획수를 뺀 본체 획수)로 거리를 계산하면 쉽게 비슷한 한자를 묶을 수 있다.
이것들은 의미상 함께 묶인 것이다. 이렇게 의미상으로 관련 있는 것을 찾아 묶어 정리하면 작문할 때 편리하다. 예를 들어 사람, 동물(하늘/땅/바다), 식물(나무/풀/꽃/열매), 물질, 건물, 지형 등으로 분류해서 가지고 있으면 작문할 때 도움이 된다. (허나 한자로 작문할 일이 없으니)
대부분의 한자 단어가 2~3 음절로 사용 된다. 한 음절이 한 단어인 경우는 그 수가 많지 않다. 문법 단어이거나 고대부터 자리를 굳힌 단어들이다. 문명 시대에 만들어진 단어들은 대부분 2음절 이상이다. 한자 단어로 묶는 것도 의미 중심으로 묶는 것이다.
- 반의어 결합 : 상하(上下), 선악(善惡), 고저(高低), 장단(長短), 강약(强弱)
- 동의어 결합 : 황공(惶恐), 공황(恐惶), 관습(慣習), 습관(習慣), 고독(孤獨), 독고(獨孤)
- 접두사 결합 : 무색(無色), 무취(無臭), 무리(無理), 무법(無法), 비리(非理), 불법(不法)
- 접미사 결합 : 미적(美的), 도덕적(道德的), 부정적(否定的), 긍정적(肯定的)
- 형용사 명사 결합 : 미인(美人), 미남(美男), 추녀(醜女), 악인(惡人), 성인(聖人), 범인(犯人)
- 동사 목적어 결합 : 독서(讀書), 귀향(歸鄕), 귀국(歸國), 귀가(歸家)
- 부사 동사 결합 : 속행(速行), 서행(徐行), 빈발(頻發), 강행(强行)
3. 모양으로 묶기

네이버, 다음 파자 검색기를 통해서 비슷한 모양을 가진 한자(형성/회의)를 검색할 수 있다. 모양이 비슷해서 헛갈리는 복잡한 한자들은 묶어서 외우면 차이점에 집중해서 구분하기 쉬워진다. 이렇게 하는 것은 한자 판독 능력 향상에 아주, 매우 도움이 된다. 그런데 네이버, 다음 파자 검색기는 완벽하지 않다. 약간 엉터리다. 빠진 한자들이 많다. 100% 믿지 말라.
비슷한 크기로 좌우 결합, 상하 결합한 한자의 경우 어느 것이 부수인지 파악하기 어렵다. 그런 것은 거의 기초 한자다. 이 중에 상하로 결합한 것들, 그 중에 단독으로 거의 사용하지 않고 다른 한자의 부품 한자로 많이 보이는 것이 있다. 고로 세로로 결합한 것들은 모두 기초 한자로 외워두면 좋다. 좌우대칭, 같은 형상 반복, 상하결합 한자는 보면 기초 한자라고 생각하고 모아둔다.
옛날엔 한문을 세로로 적었기 때문에 세로로 결합한 한자가 아마도 헛갈렸던 것 같다. 세로로 결합한 한자는 점차 단독 사용이 줄고 옆에 부수가 추가 된다. 예를 들어 원래 한자도 A라는 뜻인데 좌우에 부수가 추가 되어도 같은 A라는 뜻인 경우가 많다. 가로로 결합한 한자는 그냥 그대로 계속 쓰인 것 같다.
4. 소리로 묶기
소리로 묶을 경우는 피곤하게 파자 검색기를 사용하지 않고도 쉽게 형성 문자들을 함께 모을 수 있다. 대신 소리를 초성, 중성, 종성으로 나누고 초성과 중성은 다음과 같이 나누고 가나다 순서를 좀 바꿔야 한다.
- 초성 : 목구멍(그크끄, 흐으), 혀(느르, 드트뜨, 즈츠쯔, 스쓰), 입술(므, 브쁘프)
- 중성 : 단모음(아어애에오우으이), 이중모음(야여요유얘예), 이중모음(와워왜웨외위의)
초성, 중성에서 비슷한 소리가 이어지도록 순서를 정한 후, 소리 사이의 거리와 획수(부수 획수를 뺀 본체 획수)로 거리를 계산하면 쉽게 비슷한 한자를 묶을 수 있다.
옥편의 경우
- 부수→획수
- 획수→부수
- 독음→부수
형태로 정리가 되어 있다. 이 중에서 독음→부수 조합은 불편하다. 차라리 획수→독음, 독음→획수 조합이 더 찾기 편하다. 비슷한 모양이 뭉쳐 있어 더 찾기 쉽다.
낡은 것들이 6.25를 겪고 이승만 시대를 살아 봤냐고 물어 보면? 이미 그 세대는 80대이고 거의 50%가 죽었다. (왜? 평균 수명이 80세니까.) 그리고 그 시대를 진짜 살았던, 친일파, 빨갱이, 독립군이 누구인지 알았던, 그 당시 중장년 층(80대 이상)이었던 사람들이 남긴 기록 없이 그 이후 세대는 진실을 모른다.
| 년도 | 사건 | 나이(세대 차이) | ||||||
| 1945 | 8.15 광복 | 15 | 5 | |||||
| 1950 | 6.25 한국전쟁 | 20 | 10 | 0 | ||||
| 1955 | 25 | 15 | 5 | |||||
| 1960 | 4.19 민주혁명 | 30 | 20 | 10 | 0 | |||
| 1965 | 35 | 25 | 15 | 5 | ||||
| 1970 | 40 | 30 | 20 | 10 | 0 | |||
| 1975 | 45 | 35 | 25 | 15 | 5 | |||
| 1980 | 5.18 광주학살 | 50 | 40 | 30 | 20 | 10 | 0 | |
| 1985 | 55 | 45 | 35 | 25 | 15 | 5 | ||
| 1990 | 냉전종식 | 60 | 50 | 40 | 30 | 20 | 10 | 0 |
| 1995 | IMF | 65 | 55 | 45 | 35 | 25 | 15 | 5 |
| 2000 | 월드컵 | 70 | 60 | 50 | 40 | 30 | 20 | 10 |
| 2005 | 섭프라임모기지 | 75 | 65 | 55 | 45 | 35 | 25 | 15 |
| 2010 | 독재부활? | 80 | 70 | 60 | 50 | 40 | 30 | 20 |
| 2015 | 독재부활? | 85 | 75 | 65 | 55 | 45 | 35 | 25 |
| 2020 | 90 | 80 | 70 | 60 | 50 | 40 | 30 | |
지금 낡은 것들(60대~80대)은 한국 전쟁을 겪지 않았다. 그 당시 아직 10대 이하였으니 직접 전투도 하지 않았고, 학살도 당하지 않았다. 이들의 기억은 자신의 단편적 경험(배고픔) + 어른에게서 들은 얘기다. 전쟁과 배고픔을 겪지 않았던 나의 아버지 또한 그런 소리를 하는 것을 보니, 그냥 들은 얘기를 지 얘기처럼 하는 습관이다. 나이 들면 젊은 애들 말 좀 듣고 살아라. 그래야 꼰대 소리 안 듣지.
이승만 시대 10대~20대를 보낸 지금 낡은 것들(70대~80대)은 전쟁 후유증으로 제대로 된 교육도 받지 못 했고, 공부할 시간도 부족했다. 통학 시간만 몇 시간이었다. 교육은 국가의 책임이 아닌 각자의 책임이어서 돈 없는 집안엔 초졸, 중졸도 많다. 시골엔 명문 중학교가 있을 정도니까. 거기에 친일 식민 사관을 세뇌 교육 당했으니 한마디로 한국에서 가장 무식한 세대이다.
허나 낡은 세대 중에도 일부는 제대로 교육을 받아 이승만을 쫓아 냈듯이, 중년층 일부도 전두환 독재를 물리쳤고, 젊은 세대 중 일부는 걱정원 댓글 용역이나 하고 있을 정도로 열등한 것들도 있다. 양심 있는 배운 자들이 독재에 협력하지 않을 때 독재는 하층민 깡패들을 고용한다. 정치 깡패라고 하지?
언론 선동, 역사 왜곡, 세뇌 교육의 영향이 참으로 크다. 허나 신이 사람들 마음속에 심어 놓은 3신(이성, 양심, 용기)에 의지하면 언제나, 언젠가 정답을 구할 수 있다.
이승만 시대 10대~20대를 보낸 지금 낡은 것들(70대~80대)은 전쟁 후유증으로 제대로 된 교육도 받지 못 했고, 공부할 시간도 부족했다. 통학 시간만 몇 시간이었다. 교육은 국가의 책임이 아닌 각자의 책임이어서 돈 없는 집안엔 초졸, 중졸도 많다. 시골엔 명문 중학교가 있을 정도니까. 거기에 친일 식민 사관을 세뇌 교육 당했으니 한마디로 한국에서 가장 무식한 세대이다.
허나 낡은 세대 중에도 일부는 제대로 교육을 받아 이승만을 쫓아 냈듯이, 중년층 일부도 전두환 독재를 물리쳤고, 젊은 세대 중 일부는 걱정원 댓글 용역이나 하고 있을 정도로 열등한 것들도 있다. 양심 있는 배운 자들이 독재에 협력하지 않을 때 독재는 하층민 깡패들을 고용한다. 정치 깡패라고 하지?
언론 선동, 역사 왜곡, 세뇌 교육의 영향이 참으로 크다. 허나 신이 사람들 마음속에 심어 놓은 3신(이성, 양심, 용기)에 의지하면 언제나, 언젠가 정답을 구할 수 있다.