
2026-02-24 수정
나중에 번역 도움이, 작문 도움이 만들 때 참고할 내용이다. 어느 컴퓨터 사전에 등록된 단어를 분석한 것이다. 어학 사전의 단어 수는 거의 대동소이할 것이다.
- 영한사전에 등록된 단어 : 약13만6천개 = 단일 약8만4천개 + 복합 약5만2천개
- 국어사전에 등록된 단어 : 약5만3천개
- 발음파일 있는 영어단어 : 약1만1천개
한국어의 경우 동사, 형용사의 단어 변형(굴절, 파생어)이 포함되어 있지 않다. 원형만 알면 문법 규칙으로 변형을 알 수 있기 때문이다. 단어 수가 영어보다 적은 게 아니다.
예) 아름답다(형.서술) ↔ 아름다운(형.수식) ↔ 아름다움(명) ↔ 아름답기(명) ↔ 아름답게(부)
영어의 경우 동사, 형용사의 파생어까지 포함되어 있어서 단어 수가 많아 보인다. 거기에 2개 이상 단어가 뭉친 복합 단어(공백이나 -로 구분)도 포함되어 있다. 두 단어가 어떤 구분 기호 없이 바로 붙은 경우도 있는데 기계적으로 구분이 불가능하여 여기서 단일 단어로 취급했다. 원형만 알면 파생어 유추가 가능하니 실제론 영어 단어 수는 많지 않다.
예) beauty(명) ↔ beautiful(형) ↔ beautifully(부) ↔ beautify(동)
보통 약 1만 개의 단어를 알면 어휘에는 문제가 없다. 실제로 전자 사전에 발음 음성 파일이 등록된 경우가 거의 1만1천 개이다. 나머지 대부분의 단어가 사용되지 않는 죽은 단어거나 전문 분야에서 사용하는 전문 용어이다.
빠른 검색을 위해선 단어 목록의 처음부터 비교하는 것이 아니라 단어 특징에 따라 검색표를 세분하고 단어 특징을 분석해서 해당 검색표로 가서 비교하는 것이다. 우리도 사전을 찾을 때 첫 글자를 보고 그 글자로 시작하는 부분부터 찾는다. 고로 단어 특징을 보도록 하자.
단어 특징 분석
빠른 검색을 위해선 단어 목록의 처음부터 비교하는 것이 아니라 단어 특징에 따라 검색표를 세분하고 단어 특징을 분석해서 해당 검색표로 가서 비교하는 것이다. 우리도 사전을 찾을 때 첫 글자를 보고 그 글자로 시작하는 부분부터 찾는다. 고로 단어 특징을 보도록 하자.
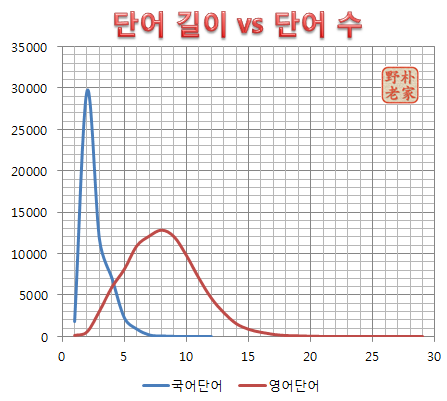
한국어는 2음절 단어가 가장 많다. 중국의 한자어의 경우도 대체로 2음절인 경우가 가장 많다. 1음절이 100개의 소리만 나도 2음절이면 1만의 단어가 된다. 영어는 8개 문자(약 3~4음절)인 경우가 가장 많다. "초성+중성+종성=음절"이라고 보면 영어에선 2~3문자가 1음절이다.

발음 파일이 등록된 자주 사용하는 약 1만1천개의 영어 단어의 경우는 길이가 6개 문자인 경우(2~3음절)가 가장 많다. 한국어, 중국어 평균 음절 수와 거의 비슷하다. 역시 자주 사용하는 단어에선 2~3음절이 대세다.



단어의 첫 글자를 보고 사전에서 단어를 찾는 것처럼 검색표를 분할하면 검색 속도가 빠르다. 수가 적은 j+k+q+x+y+z 6개는 뭉쳐도 된다. 단어의 끝 글자의 경우 빈부격차가 심하다. 역시 어느 나라 말이나 어미에 특징이 있어서 어미만 알아들어도 그 언어가 뭔지 알 수 있다. 접미사나 어미는 자주 반복되기 때문이지. 고로 어미를 특징으로 잡으면 검색이 어렵겠다.

단어 앞에 나오는 이중 자음도 하나의 글자처럼 취급한다고 하자. 로마 알파벳이 모자라서 2개 철자를 뭉쳐 하나의 소리를 표현하는 경우는 흔하다. 예를 들어 영어의 sh~, ch~, th~, ph~, st~, sk~, sp~, sq~ 등을 하나의 자음으로 취급하면 검색표를 더 세분할 수 있다. 비슷한 원리를 좀 더 확장하면 첫 모음 부분까지 포함해서 특징으로 삼는 것이다. 기계적으로 자음 모음을 구분할 수 있기 때문에 첫 모음까지를 특징으로 삼아도 된다.

단어 특징 = 시작 알파벳 + 단어 길이로 했을 경우 beautiful은 b6 또는 6b 검색표에 포함 된다. 숫자 0 ~ 9는 단어 길이 3 ~ 12에 대응한다. 3 이하와 12 이상은 수가 적으니 뭉친다.
이렇게 하면 시작 문자 특징 21개 * 10길이 = 210개의 작은 검색표가 만들어지는데 최악의 경우 s5 표의 270개 단어만 비교하면 1만 개의 단어 중에 원하는 단어를 찾을 수 있다. 여기서 s5 표만 더 잘게 자를 수도 있다.
여기에 단어 출현 빈도로 정렬을 해 두면 검색 속도가 더 빨라진다. 문법 단어인 관사, 대명사, 의문사, 접속사, 전치사, 첨사, 조동사 등은 출현 빈도가 매우 높다. 이런 것들은 검색표의 앞부분에 배치한다. 또는 프로그램 코드에 삽입해 버린다.

최악의 경우 co~ 조합에서 522회의 비교를 해야 한다. 자주 사용하는 접두사와 접미사가 있어 특정 철자에 단어들이 많이 모인다. 이런 경우 검색 특징으로는 좋지 못 하다. 고로 접두사와 접미사를 감안해서 더 세분하는 작업이 필요하다. 모두에게 기계적으로 같은 규칙을 적용할 필요는 없다. 세력과 규모에 따라 비례하여 처리하는 게 좋다.

접두사보다는 접미사 쪽이 더 빈부격차가 심하다. 이 말은 상당히 많은 단어들이 접미사가 붙은 파생어란 의미고, 대부분의 언어에서 단어의 엉덩이 부분에 반복되는 패턴이 나타난다. 그러나 예외가 있기 때문에 기계적으로 단어의 엉덩이 부분을 분석해서 원형을 찾는 방식은 좋지 않다. ~er, ~ing, ~ion, ~ment, ~ly 등에 압도적으로 집중 되어 있다.
기초 단어들도 엉덩이 부분이 비슷한 것들이 많은데 발음도 거의 비슷해서 규칙성이 있다. 예를 들어 "자음+모음+자음+e"로 끝나는 짧은 단어들을 보면 모음 발음이 대단히 규칙적이다. (이건 영어 발음에도 규칙 있다는 글 참고)

보통 전자 사전에 키보드로 입력을 하여서 찾는데 타자가 느리면 불편하다. Excel과 HTML5를 이용해서 종이 사전에서 검색하는 것처럼 만들 수 있다. 100개씩 100페이지면 1만개의 단어이다. 첫 페이지에서 100개 단어 중에 1개를 선택하면 다음 페이지에서 100개 단어 중에 검색 단어를 찾는 방식이다.

단어를 ABC순서로 정렬하여 100개씩 자동으로 끊고 싶을 때 갑자기 단어 길이가 짧아지는 지점을 찾아 끊으면 파생어끼리 묶여 같은 페이지에 들어가게 된다. 이 원리를 이용해서 마우스 클릭 단 2회로 1만개 단어 중에서 원하는 것을 찾는 사전을 만들 수 있다.
전자 사전의 경우 전문적으로는 해시 함수(hash function) 이용. 앞에 보인 여러 특징들이 해시 값에 해당한다. 앞과 뒤와 길이를 섞으면 적절한 해시 값이 됨을 보였다.
아래는 스마트폰에서도 사용할 수 있을 정도로 직접 만든 것이다. 이건 네이버/다음 검색을 사용하지 않고 직접 검색표를 만들었다. 수 많은 페이지를 표로 만들며 링크를 걸어야 하기 때문에 Excel 계산과 Macro를 섞어 잘 활용해야 만들 수 있다. 10 페이지 정도는 사람이 직접 만들 수 있다. 그런데 100페이지 이상이라면? 만들다 보면 머리가 몽롱해진다. 클릭 3회면 원하는 결과에 도달할 수 있다. 이렇게 하려면 적당한 크기로 목록을 분리하는 기술이 필요하다. 마지막 단어 설명 파일은 한컴 사전을 베끼면 된다. 재미 있어서 역순 검색(엉덩이 비슷한 것들), 운모 검색(초성을 제외한 모음+받침 소리가 비슷한 것들)도 만들었지. ㅋㅋㅋㅋ

이 방법의 문제는 단어 하나에 파일 하나가 연결 되어 있어 파일 수가 너무 많다는 것이다. 단어 수 = 파일 수. 컴퓨터는 클러스터 단위로 저장하기 때문에 파일이 아무리 작아도 클러스터 하나를 잡아 먹는다. 용량 면에서 불리하다. 그리고 파일 시스템의 검색 기능을 이용해서 파일을 찾아 여는 것이라 DB보다는 부담이 된다. O/S가 고생을 하는 것이지. 그래서 인공 지능이 알려 준 방법이 있는데, DB를 웹 브라우저로 바로 검색할 수 있는 방법이다. 그런데 너무 전문적이라서 이런 게 있다는 것만 알아 두자.
발음 파일이 등록된 자주 사용하는 약 1만1천개의 영어 단어의 경우는 길이가 6개 문자인 경우(2~3음절)가 가장 많다. 한국어, 중국어 평균 음절 수와 거의 비슷하다. 역시 자주 사용하는 단어에선 2~3음절이 대세다.
발음 음성 파일이 등록된 자주 사용하는 약 1만1천 개의 영어 단어에서 기계적으로 음절을 계산한 결과 역시 2음절이 가장 많다. (그럼 그렇지) 여기서 음절이란 대충 단모음, 이중모음 등 모음이 뭉친 덩어리의 개수를 말한다. 음절의 중심은 초성이나 받침이 아니라 모음이니까. 한국어나 영어나 결국 대부분의 단어는 5음절 미만이다.
단어의 첫 글자를 보고 사전에서 단어를 찾는 것처럼 검색표를 분할하면 검색 속도가 빠르다. 수가 적은 j+k+q+x+y+z 6개는 뭉쳐도 된다. 단어의 끝 글자의 경우 빈부격차가 심하다. 역시 어느 나라 말이나 어미에 특징이 있어서 어미만 알아들어도 그 언어가 뭔지 알 수 있다. 접미사나 어미는 자주 반복되기 때문이지. 고로 어미를 특징으로 잡으면 검색이 어렵겠다.
단어 앞에 나오는 이중 자음도 하나의 글자처럼 취급한다고 하자. 로마 알파벳이 모자라서 2개 철자를 뭉쳐 하나의 소리를 표현하는 경우는 흔하다. 예를 들어 영어의 sh~, ch~, th~, ph~, st~, sk~, sp~, sq~ 등을 하나의 자음으로 취급하면 검색표를 더 세분할 수 있다. 비슷한 원리를 좀 더 확장하면 첫 모음 부분까지 포함해서 특징으로 삼는 것이다. 기계적으로 자음 모음을 구분할 수 있기 때문에 첫 모음까지를 특징으로 삼아도 된다.
단어 특징 = 시작 알파벳 + 단어 길이로 했을 경우 beautiful은 b6 또는 6b 검색표에 포함 된다. 숫자 0 ~ 9는 단어 길이 3 ~ 12에 대응한다. 3 이하와 12 이상은 수가 적으니 뭉친다.
이렇게 하면 시작 문자 특징 21개 * 10길이 = 210개의 작은 검색표가 만들어지는데 최악의 경우 s5 표의 270개 단어만 비교하면 1만 개의 단어 중에 원하는 단어를 찾을 수 있다. 여기서 s5 표만 더 잘게 자를 수도 있다.
여기에 단어 출현 빈도로 정렬을 해 두면 검색 속도가 더 빨라진다. 문법 단어인 관사, 대명사, 의문사, 접속사, 전치사, 첨사, 조동사 등은 출현 빈도가 매우 높다. 이런 것들은 검색표의 앞부분에 배치한다. 또는 프로그램 코드에 삽입해 버린다.
단어가 원형+s , 원형+ing, 원형+ed, 원형+er로 끝나는 규칙적인 경우는 꼬리를 잘라내면 원형을 쉽게 얻을 수 있다. 그 외의 유명한 접두사(예: re~)와 접미사(예: ~ment, ~ful)의 경우는 단어 특징 분석 후에 원형을 추출하여 찾을 수 있다. 그러나 항상 예외가 문제인데 예외는 암기 외엔 답이 없다. 고로 단어 형태 분석은 기계적으로 안 하는 게 좋다. 변형 그 자체로 검색하여 원형을 찾는 게 더 안전하다. 어차피 단어를 보고 규칙/예외를 구분해야 하니 계산보단 기억을 이용하는 게 낫다.

모든 단어는 거의 최소한 2개 글자 이상이다. 고로 앞의 2개 글자 조합을 특징으로 삼아 검색표를 만들 수도 있다. 표를 보면 자음+모음=음절, 모음+자음=음절의 경우가 많다. 자음+자음=2중자음, 모음+모음=2중모음인 경우는 드물다. 자음+자음인 경우 하나의 자음처럼 쓰이는 것들이 있다. 이런 것은 2개 자음을 하나의 자음으로 취급하고 앞 3개 글자를 특징으로 취할 수도 있다. 아니면 자음/모음 뭉치를 구분 해서 첫음절을 취할 수도 있다.
최악의 경우 co~ 조합에서 522회의 비교를 해야 한다. 자주 사용하는 접두사와 접미사가 있어 특정 철자에 단어들이 많이 모인다. 이런 경우 검색 특징으로는 좋지 못 하다. 고로 접두사와 접미사를 감안해서 더 세분하는 작업이 필요하다. 모두에게 기계적으로 같은 규칙을 적용할 필요는 없다. 세력과 규모에 따라 비례하여 처리하는 게 좋다.

접두사보다는 접미사 쪽이 더 빈부격차가 심하다. 이 말은 상당히 많은 단어들이 접미사가 붙은 파생어란 의미고, 대부분의 언어에서 단어의 엉덩이 부분에 반복되는 패턴이 나타난다. 그러나 예외가 있기 때문에 기계적으로 단어의 엉덩이 부분을 분석해서 원형을 찾는 방식은 좋지 않다. ~er, ~ing, ~ion, ~ment, ~ly 등에 압도적으로 집중 되어 있다.
기초 단어들도 엉덩이 부분이 비슷한 것들이 많은데 발음도 거의 비슷해서 규칙성이 있다. 예를 들어 "자음+모음+자음+e"로 끝나는 짧은 단어들을 보면 모음 발음이 대단히 규칙적이다. (이건 영어 발음에도 규칙 있다는 글 참고)

반복 되는 접두사와 접미사가 많지만 그 둘이 함께 나타나기는 드물다. 고로 첫 글자와 끝 글자를 조합해서 특징을 삼아 검색표를 만들 수도 있다. 첫 글자와 끝 글자 사이에는 자음과 모음으로 음절을 만드는 상관성도 없다. 이 경우는 s~e 검색표에서 최악 285회의 비교를 해야 한다. 앞에서 본 것들보단 검색 특징으로서 좋은 편이다.
앞의 검색 특징을 모두 활용하면 26개 시작 문자 * 26개 끝 문자 * 10단계 길이 구분 = 6760개 검색표가 만들어진다. 거의 특징 1개에 평균 2개 단어가 할당되어 검색을 총알같이 할 수 있겠다. 실제론 빈부 격차가 있기 때문에 단어가 전혀 없는 표도 있어서 검색표는 그리 많지 않을 것이다.
문제는 2~3개 단어가 연속으로 나타나서 한 단어처럼 쓰이는 숙어, 또는 서로 떨어져서 호응관계인 숙어의 경우 첫 단어를 보고 그 다음 단어를 함께 검색할 것인지 판단할 필요가 있다. 이 경우도 2개 ~ 3개 단어 조합의 숙어가 가장 많을 것으로 예상할 수 있고, 이 경우도 같은 방법으로 검색표를 만들 수 있겠다.
빠른 사전 검색기 만들기
보통 전자 사전에 키보드로 입력을 하여서 찾는데 타자가 느리면 불편하다. Excel과 HTML5를 이용해서 종이 사전에서 검색하는 것처럼 만들 수 있다. 100개씩 100페이지면 1만개의 단어이다. 첫 페이지에서 100개 단어 중에 1개를 선택하면 다음 페이지에서 100개 단어 중에 검색 단어를 찾는 방식이다.
단어를 ABC순서로 정렬하여 100개씩 자동으로 끊고 싶을 때 갑자기 단어 길이가 짧아지는 지점을 찾아 끊으면 파생어끼리 묶여 같은 페이지에 들어가게 된다. 이 원리를 이용해서 마우스 클릭 단 2회로 1만개 단어 중에서 원하는 것을 찾는 사전을 만들 수 있다.
전자 사전의 경우 전문적으로는 해시 함수(hash function) 이용. 앞에 보인 여러 특징들이 해시 값에 해당한다. 앞과 뒤와 길이를 섞으면 적절한 해시 값이 됨을 보였다.
간단하고 직접적인 해시 함수를 보면 영어의 각 문자를 숫자(a~z=0~25)로 바꾸고, 문자열의 길이는 진수(26)로 반영하는 것이다. abc는 0*26² + 1*26¹ + 2 또는 0 + 1*26¹ + 2*26²이 되는 방식이다. 이렇게 하면 모든 문자열은 오직 하나의 독특한 숫자를 가지게 되는데 공간 낭비가 너무 많다. 단어의 길이가 평균 9라면 26의 9승인 5,4295,0367,8976(5조)가 나오게 되어 숫자가 너무 커지는 문제(오버플로우)가 발생한다. 그래서 진수를 26이 아닌 더 작은 값으로 취하는 방법도 있다. 또한 덧셈이 아닌 XOR을 시키는 방법도 있다.
- 16비트라면 6,5536(6만)까지 표현 가능하다.
- 32비트라면 42,9496,7296(42억)까지는 표현 가능하다.
- 64비트라면 1844,6744,0737,0955,1616(1844경)까지 표현 가능하다.
평균 10개의 단어가 같은 해시 값을 가지게 하려면 단어 1만개를 1000개의 작은 표로 분할한다. 해시 값을 1000으로 나누어 나머지만 취하는 방법이 있는데 이건 결국 뒤의 몇 글자 또는 앞의 몇 글자만 취해서 해시 값을 만든 것과 다름없다. 접두사와 접미사는 자주 사용되기 때문에 몰리는 현상이 있어 좋지 않았다. 그래서 시작과 끝의 몇 글자를 지우고 중간(어간)만 가지고 해시 값을 구하기도 한다. 또는 시작과 끝의 몇 글자를 묶어 하나의 정수(문자)로 취급하는 방법도 있다.
아래는 사용한 HTML5 코드이다. (HTML 문법 모호한 부분이 정말 많다.) 검색은 네이버/다음을 이용한다. 고로 인터넷이 연결 되어야 한다. 자체 검색표로 할 경우 위와 같이 표를 잘게 나누어야 한다.
Text 파일을 UTF-8, UTF-16로 저장한 후 확장자를 HTML로 바꾸면 정상동작한다.
네이버/다음에서 일어/중어의 경우 한자 검색, 소리(가나/병음) 검색 2가지 모두 가능함.
일어/중어 기타 언어의 경우 유니코드를 사용해야 검색이 된다. ANSI나 옛날 코드는 무시.
영단어/중단어/일단어 부분에 검색할 단어를 넣으면 된다.
<!DOCTYPE html>
<html>
<head>
<title>네이버 다음 사전 검색법</title>
<meta charset="UTF-8">
</head>
<body>
<a href="http://dic.daum.net/search.do?q=영단어&dic=eng" target=_blank>영단어</a>
<a href="http://dic.daum.net/search.do?q=일단어&dic=jp" target=_blank>일단어</a>
<a href="http://dic.daum.net/search.do?q=중단어&dic=ch" target=_blank>중단어</a>
<a href="https://endic.naver.com/search.nhn?query=영단어" target=_blank>영단어</a>
<a href="https://ja.dict.naver.com/search.nhn?query=일단어" target=_blank>일단어</a>
<a href="https://zh.dict.naver.com/#/search?query=중단어" target=_blank>중단어</a>
</body>
</html>
<!DOCTYPE html>
<html>
<frame name=이름B src="frame_b.htm">
</frameset>
</html>
<!DOCTYPE html>
<html>
<body>
<iframe src="단어목록파일이름.html" name=이름 width=폭 height=높이>
오류설명
</iframe>
</body>
</html>
<table>
<colgroup>
Text 파일을 UTF-8, UTF-16로 저장한 후 확장자를 HTML로 바꾸면 정상동작한다.
네이버/다음에서 일어/중어의 경우 한자 검색, 소리(가나/병음) 검색 2가지 모두 가능함.
일어/중어 기타 언어의 경우 유니코드를 사용해야 검색이 된다. ANSI나 옛날 코드는 무시.
영단어/중단어/일단어 부분에 검색할 단어를 넣으면 된다.
<!DOCTYPE html>
<html>
<head>
<title>네이버 다음 사전 검색법</title>
<meta charset="UTF-8">
</head>
<body>
<a href="http://dic.daum.net/search.do?q=영단어&dic=eng" target=_blank>영단어</a>
<a href="http://dic.daum.net/search.do?q=일단어&dic=jp" target=_blank>일단어</a>
<a href="http://dic.daum.net/search.do?q=중단어&dic=ch" target=_blank>중단어</a>
<a href="https://endic.naver.com/search.nhn?query=영단어" target=_blank>영단어</a>
<a href="https://ja.dict.naver.com/search.nhn?query=일단어" target=_blank>일단어</a>
<a href="https://zh.dict.naver.com/#/search?query=중단어" target=_blank>중단어</a>
</body>
</html>
<!DOCTYPE html>
<html>
<frameset cols="50%,50%"> 또는 <frameset rows="50%,50%">
<frame name=이름A src="frame_a.htm"><frame name=이름B src="frame_b.htm">
</frameset>
</html>
<!DOCTYPE html>
<html>
<body>
<iframe src="단어목록파일이름.html" name=이름 width=폭 height=높이>
오류설명
</iframe>
</body>
</html>
<table>
<colgroup>
<col span=적용칼럼A width=칼럼폭>
<col span=적용칼럼B width=칼럼폭>
<col span=적용칼럼C width=칼럼폭>
</colgroup>
<tr valign=상하중 align=좌우중>
<td>단어A<BR id="단어위치"></td>
<td>단어B<BR id="단어위치"></td>
<td>단어C<BR id="단어위치"></td>
<td>단어B<BR id="단어위치"></td>
<td>단어C<BR id="단어위치"></td>
</tr>
</table>
<a href="단어목록파일이름.html#단어위치" target="표시위치지정">단어</a>
<audio controls>
<source src="단어발음파일이름.mp3" type="audio/mpeg">
</audio> 단어
</table>
<a href="단어목록파일이름.html#단어위치" target="표시위치지정">단어</a>
- _blank : 새 창과 탭에서 열기
- _self : 디폴트, 현재 프레임에서 열기
- _parent : 부모 프레임에서 열기
- _top : 윈도우 전체에서 열기
- framename : 지정한 이름의 프레임에서 열기
<audio controls>
<source src="단어발음파일이름.mp3" type="audio/mpeg">
</audio> 단어
아래는 스마트폰에서도 사용할 수 있을 정도로 직접 만든 것이다. 이건 네이버/다음 검색을 사용하지 않고 직접 검색표를 만들었다. 수 많은 페이지를 표로 만들며 링크를 걸어야 하기 때문에 Excel 계산과 Macro를 섞어 잘 활용해야 만들 수 있다. 10 페이지 정도는 사람이 직접 만들 수 있다. 그런데 100페이지 이상이라면? 만들다 보면 머리가 몽롱해진다. 클릭 3회면 원하는 결과에 도달할 수 있다. 이렇게 하려면 적당한 크기로 목록을 분리하는 기술이 필요하다. 마지막 단어 설명 파일은 한컴 사전을 베끼면 된다. 재미 있어서 역순 검색(엉덩이 비슷한 것들), 운모 검색(초성을 제외한 모음+받침 소리가 비슷한 것들)도 만들었지. ㅋㅋㅋㅋ

이렇게 만들면 DB를 만들어 검색하는 것보다는 파일 사이즈가 커진다. HTML 파일의 여러 TAG들이 추가 되기 때문이겠지. 스마트폰에서 DB 사용하는 것이 기능이 제한적이라 그렇게 마음에 들진 않는다. 네트워크 연결이 되면 그냥 네이버/다음 검색하는 게 낫겠지만 자기만의 단어집을 이렇게 만들 수 있다는 것이다.

웹 브라우저는 위와 같은 절차와 순서로 동작을 한다. 그런데 내 PC나 스마트폰의 문서를 열 때는 서버와 통신을 하지 않아도 된다. 문제는 자바스크립트인데 얘가 허락 없이 내 PC/스마트폰의 문서를 열어 보고 조작할 수 있어 차단을 해 놓는다. 오직 사람이 어떤 파일을 직접 지정해 줘야 조작을 할 수 있다. 자동 접근은 차단을 해 놓은 것이다. 그런데 내 PC에 있는 DB를 자바스크립트가 사용할 때도 위와 같은 서버들을 내 PC에 설치해야 한다. 서버를 통해서 온 건 브라우저가 내 PC 것이 아니라고 생각하기 때문이다. 서버가 보낸 것이니 서버 책임이란 거지. 이래서 매번 서버까지 실행시켜야 하니 번거롭다.


원래는 DB 서버와 웹 서버를 설치하고 브라우저는 얘들을 통해서 DB 내용을 가져 와야 하기 때문에 매우 번거롭다. 웹 브라우저는 아무 파일이나 열 수 없고 허락된 안전한 파일만 연다. 서버에서 제공하는 건 서버가 허락한 것이라 문제 없는데 브라우저가 동작하는 PC 파일은 허락된 것만 연다.
대용량 DB 서버가 필요 없는 소형 SQlite DB 파일을 사용할 수 있는데, 이걸 자바스크립트가 사용하려면 wasm이란 것이 필요하다. 웹 브라우저를 가상머신처럼 동작 시키는 어셈블리어가 담긴 파일이다. 얘는 자바스크립트보다 실행 동작이 빠르다. 문제는 얘들은 웹 브라우저가 열어도 문제 없는 파일이라고 허락 되지 않은 것이라 역시 거부를 한다.
그래서 2진 파일인 얘들을 브라우저가 열어도 문제 없는 js 문서 파일로 바꾸어 속여 메모리에 올리고, 메모리에서 문서 내용을 다시 2진 파일로 돌려 놓는 속임수를 쓴다. 코드 변환을 해야 하는 시간이 소모 되고, DB를 통으로 메모리에 올리는 것이라 너무 큰 DB는 안 된다. 뭔가 쓸 데 없는 짓 하는 느낌이다.
그리고 자바스크립트 코딩이 가능해야 한다. 인공 지능이 만들어준 코드라도 보고 고칠 수 있어야 하니까. 그래서 이렇게 번거롭게 사전 DB를 사용하는 것보다는 그냥 인터넷 네이버/다음 사전에 물어 보는 식으로 만드는 게 더 낫겠다. 다만 단어장처럼 대표적인 뜻만 단어 옆에 표시하는 게 더 효율적이겠다.
한국에 없는 것이 3가지 있다. 정의, 양심, 처녀!?
하늘은 독재 잔당이 덮고, 땅은 보수 꼴통이 덮고, 그 사이에 처녀는 쥐도 새도 모르게 멸종했다고 한다. 고아 수출 1위? 참 훌륭한 나라다. 역시 한국 놈들은 믿을 놈들이 못 된다. 학자도, 의사도, 판사도, 검사도, 변호사도, 언론인도, 국민도 독재 잔당 밑에서 잘 길들여졌다. 한국인의 말은 한국인도 믿지 않는다.
국세충이 여러분의 잠지를 감시하고 있으니 조심하라. 꼴린통은 공화당의 미인계에 넘어가 1개월 만에 루인새끼 엉덩이를 쑤셨다고 한다. 과연 보수(우익/우파)가 진보(좌익/좌파)보다 더 도덕적일까? 그들은 우릴 볼 수 있지만 우린 그들을 볼 수 없다. 젊고 예쁜 여자가 접근하면 뭔가 이상한 것이다. 처녀였다 하더라도 의심해야 한다. 처녀막 재생 수술한 요원일 수도 있다.
하늘은 독재 잔당이 덮고, 땅은 보수 꼴통이 덮고, 그 사이에 처녀는 쥐도 새도 모르게 멸종했다고 한다. 고아 수출 1위? 참 훌륭한 나라다. 역시 한국 놈들은 믿을 놈들이 못 된다. 학자도, 의사도, 판사도, 검사도, 변호사도, 언론인도, 국민도 독재 잔당 밑에서 잘 길들여졌다. 한국인의 말은 한국인도 믿지 않는다.
국세충이 여러분의 잠지를 감시하고 있으니 조심하라. 꼴린통은 공화당의 미인계에 넘어가 1개월 만에 루인새끼 엉덩이를 쑤셨다고 한다. 과연 보수(우익/우파)가 진보(좌익/좌파)보다 더 도덕적일까? 그들은 우릴 볼 수 있지만 우린 그들을 볼 수 없다. 젊고 예쁜 여자가 접근하면 뭔가 이상한 것이다. 처녀였다 하더라도 의심해야 한다. 처녀막 재생 수술한 요원일 수도 있다.
한국은 조상도 간첩으로 만드는 나라다.

댓글 없음:
댓글 쓰기